엑셀에서 텍스트 데이터를 다루다 보면 문자열에서 특정 부분만 잘라내야 하는 경우가 많습니다. 예를 들어 주민등록번호에서 생년월일을 추출하거나, 제품코드에서 카테고리 번호만 따로 뽑는 작업이 필요할 수 있습니다. 이럴 때 유용하게 사용할 수 있는 함수가 LEFT, RIGHT, MID입니다. 이 함수들은 문자열에서 앞, 뒤, 또는 중간의 특정 위치의 문자를 원하는 개수만큼 추출해주는 기능을 제공합니다. 특히 코드 분석, 텍스트 정제, 자동 보고서 작성, 데이터 포맷 통일 등 실무에서 텍스트 기반 데이터를 정리할 때 핵심적인 도구로 자주 활용됩니다.

LEFT
LEFT 함수는 문자열의 **왼쪽에서부터** 사용자가 지정한 개수만큼의 문자를 추출하는 함수입니다. 기본 구문은 =LEFT(텍스트, 문자 수)입니다. 이 함수는 예를 들어 "2025-12-10"이라는 날짜 문자열에서 연도만 추출하거나, 제품코드에서 앞자리 분류번호를 가져올 때 매우 유용합니다. 숫자든 텍스트든 상관없이 문자열로 인식되며, 앞쪽부터 필요한 정보를 자동으로 분리할 수 있습니다. 실무에서는 고객번호, 코드, 날짜 형식 등에서 앞부분 데이터를 분리해 분석할 때 널리 쓰입니다.
예제 1: 연도 추출
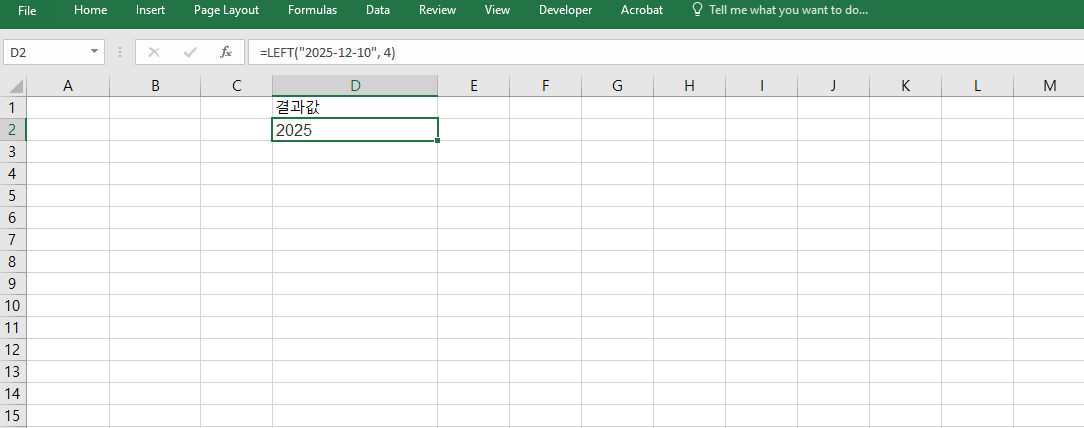
=LEFT("2025-12-10", 4)를 사용하면 결과는 "2025"가 됩니다. 이 수식은 문자열에서 왼쪽에서부터 4개의 문자를 잘라낸 것으로, 날짜 형식의 연도만 추출할 때 사용됩니다. 데이터에서 연도별 분류를 하고자 할 때 빠르게 텍스트에서 숫자 값을 정리할 수 있습니다. 서식이 일정하다면 수백 개의 셀도 동일하게 처리 가능합니다.

예제 2: 고객번호 앞자리 구분
=LEFT(A2, 3)은 A2 셀의 고객번호에서 앞의 3자리만 추출합니다. 예를 들어 "ABC12345"라는 값이 있다면 결과는 "ABC"입니다. 이는 고객 그룹 분류, 지역 코드 구분 등에서 사용할 수 있으며, 고정 길이로 구성된 문자열 데이터를 자동으로 구분할 수 있어 문서 자동화 작업에 매우 적합합니다.


예제 3: 함수와 결합 사용
=LEFT(TRIM(B2), 2)처럼 다른 문자열 정리 함수와 결합하면 불필요한 공백 제거 후 앞의 2자만 추출할 수 있습니다. 텍스트 정리가 필요한 입력값이나 복사된 데이터를 가공할 때 특히 유용하며, 실제 데이터 전처리 작업에서 실수 없이 정확한 문자 추출을 할 수 있도록 돕습니다.


RIGHT
RIGHT 함수는 문자열의 **오른쪽 끝에서부터** 지정한 개수만큼의 문자를 반환하는 함수입니다. 기본 구문은 =RIGHT(텍스트, 문자 수)이며, 주민등록번호 뒷자리, 제품 일련번호 등 뒤쪽에서 정보가 들어있는 문자열에 활용됩니다. LEFT와 정반대 개념으로 이해하면 쉬우며, 실무에서는 고정된 형식의 문자열 데이터 정리와 코드 분석 등에 자주 사용됩니다.
예제 1: 주민등록번호 뒷자리 추출
=RIGHT("900101-1234567", 7)이라는 수식은 결과로 "1234567"을 반환합니다. 이처럼 주민번호나 기타 고정 포맷의 데이터에서 뒷부분을 추출할 수 있어 보안 마스킹이나 분석용 코드 정리에 유용합니다. RIGHT는 항상 뒤에서부터 계산되기 때문에 숫자 길이가 일정한 데이터에서 더욱 효과적입니다.


예제 2: 상품 일련번호 추출
=RIGHT(A2, 5)를 사용하면 A2 셀의 문자열에서 마지막 5자리를 가져올 수 있습니다. 예를 들어 "ITM2025-00012" 라는 값이 있다면 "00012"만 추출됩니다. 이 방식은 데이터베이스 연동 또는 바코드 처리 시 숫자 부분만 자동 추출해야 하는 경우에 매우 유용합니다.


예제 3: 파일 확장자 추출
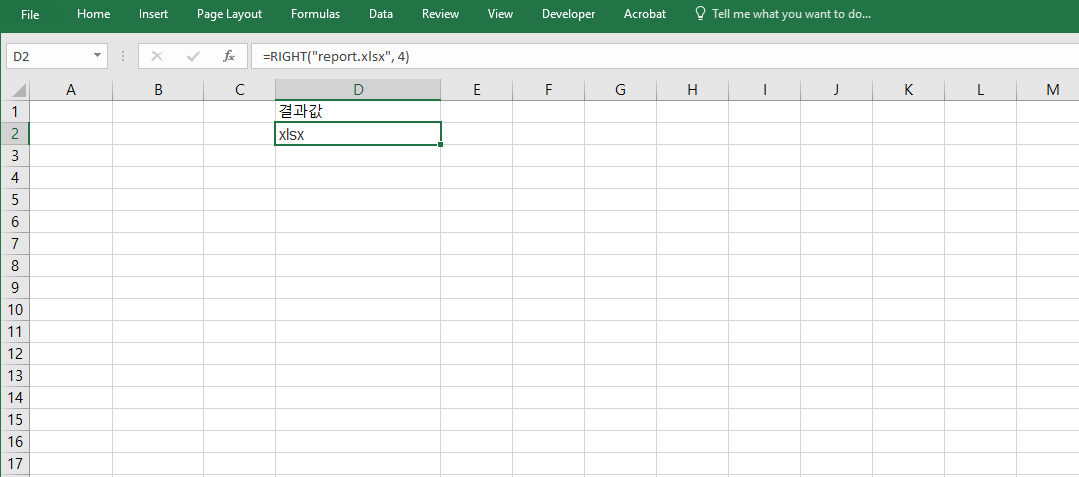
=RIGHT("report.xlsx", 4)를 입력하면 ".xlsx"가 반환됩니다. 이는 파일 이름에서 확장자만 자동으로 분리하여 문서 유형을 구분하거나 필터링할 때 자주 사용됩니다. 특히 대량의 파일 목록을 정리할 때 효율적인 분석이 가능합니다.

MID
MID 함수는 문자열에서 **중간 위치에서 시작하여 지정한 개수만큼의 문자**를 추출하는 함수입니다. 구문은 =MID(텍스트, 시작 위치, 문자 수)이며, 특정 위치의 정보를 선택적으로 뽑을 수 있기 때문에 가장 유연한 문자열 추출 함수 중 하나입니다. 특히 정형화된 코드에서 구간별로 정보가 배치된 경우, 필요한 부분만 정확하게 가져올 수 있습니다.
예제 1: 주민등록번호 생년월일 추출
=MID("900101-1234567", 1, 6)을 사용하면 앞의 6자리인 "900101"을 추출할 수 있습니다. 이 방식은 주민번호, 사업자번호, 계좌번호 등에서 특정 구간의 데이터를 추출할 때 활용되며, 사용자가 직접 시작 위치와 길이를 지정하기 때문에 매우 정확한 추출이 가능합니다.


예제 2: 제품 코드 중간 구간 추출
=MID(A2, 5, 3)는 A2 셀의 텍스트에서 5번째 자리부터 3개의 문자를 반환합니다. 예를 들어 "PRD-ABX-778"이라는 값이 있다면 결과는 "ABX"가 됩니다. 제품 카테고리 코드, 중분류 코드 등 다양한 응용이 가능하며, 고정 규칙 기반 코드 정리에 탁월한 기능을 발휘합니다.


예제 3: 특정 문자 제거 후 추출
=MID(SUBSTITUTE(A1,"-",""), 4, 3)과 같이 SUBSTITUTE 함수와 결합하면 하이픈(-)을 제거한 후 특정 위치에서 문자를 추출할 수 있습니다. 이는 사용자가 원하는 형태로 데이터를 가공하여 분석할 수 있는 대표적인 예이며, MID 함수는 이렇게 다른 텍스트 함수와 함께 쓸 때 그 활용도가 극대화됩니다.



댓글